Seja
nativamente
local.
Cresça globalmente com serviços de localização completos – texto, voz, IA e muito mais.
BLEND - A melhor escolha
Ajudando as maiores marcas, as startups mais dinâmicas e todos os demais a conquistar o mundo





O sucesso global exige que as marcas formem uma presença nativa em mercados fundamentalmente diferentes. A BLEND ajuda as empresas a localizar seus negócios usando um entendimento exclusivo do contexto, da cultura, da sutileza e do comportamento do consumidor local.
Localização de fonte única com abordagem dupla

IA e humanos

Texto e Voz

Grandes e Pequenos
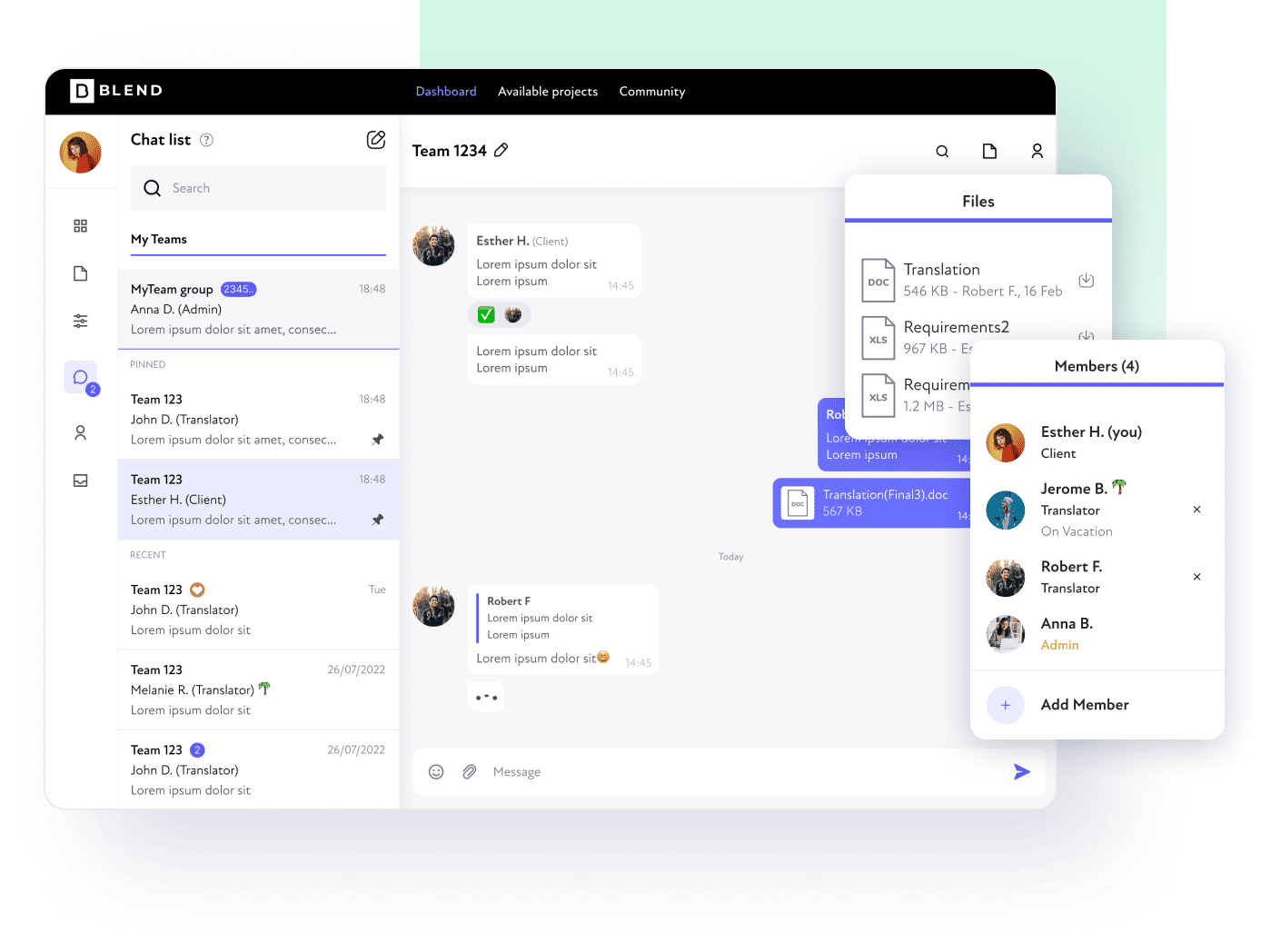
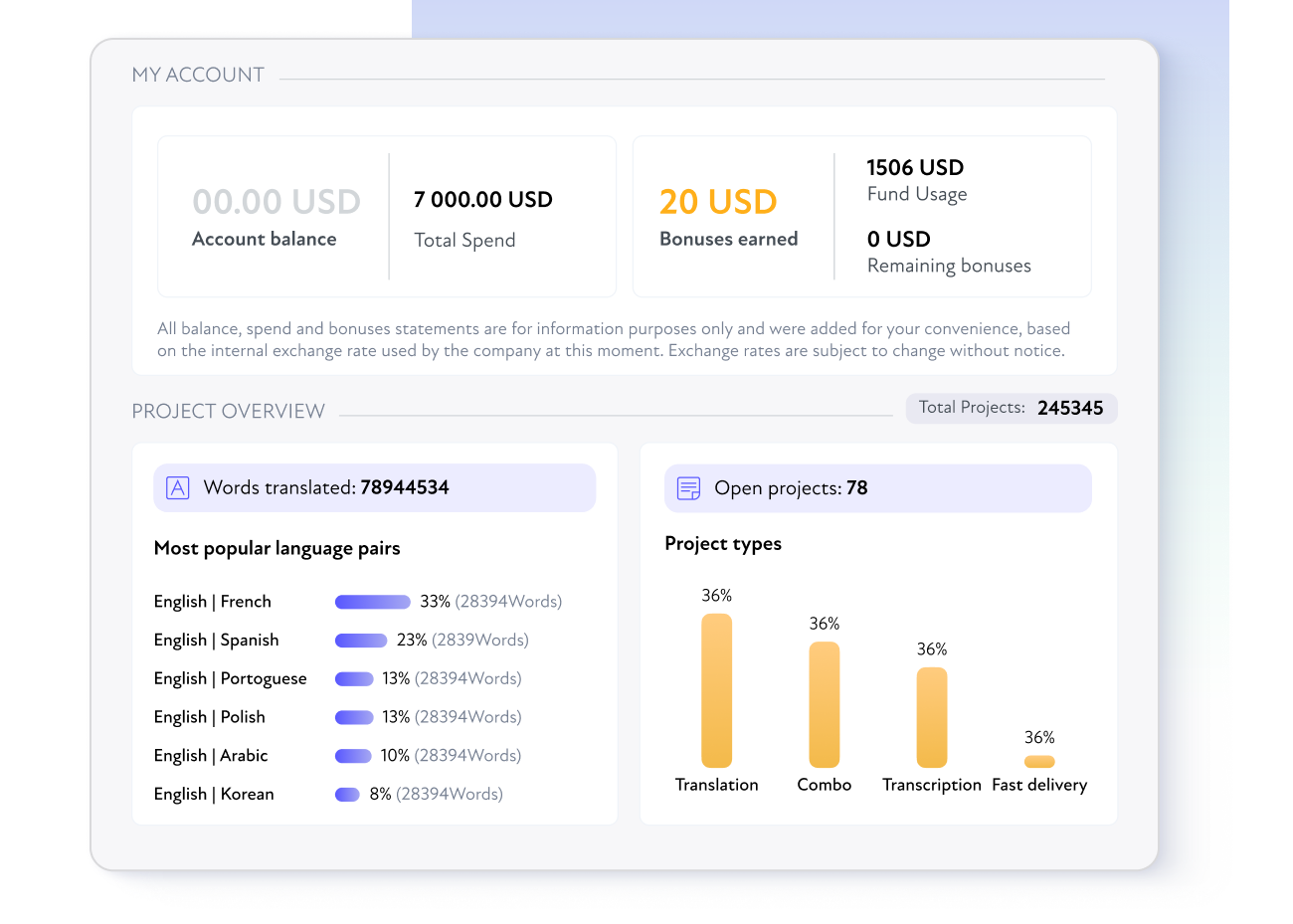
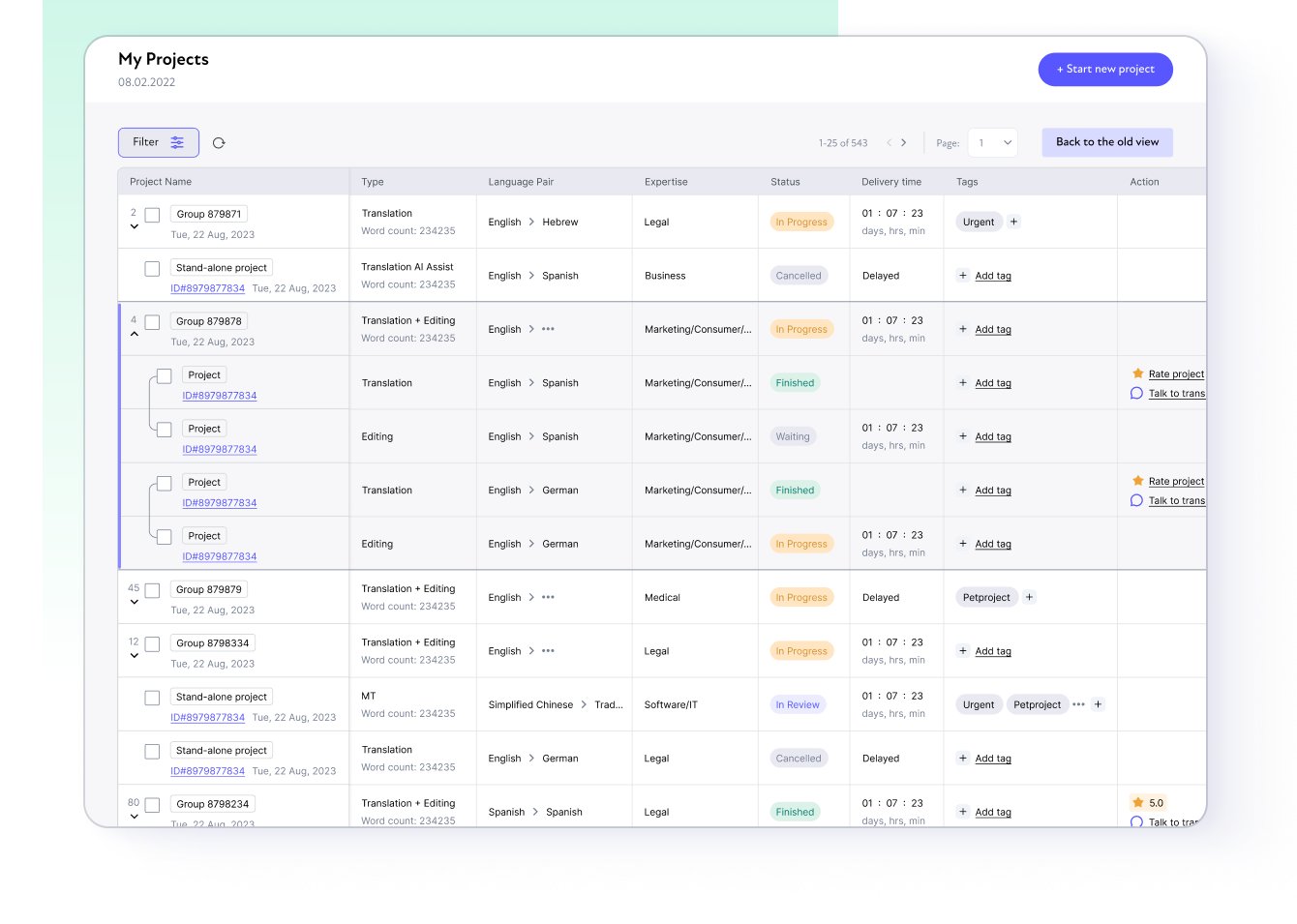
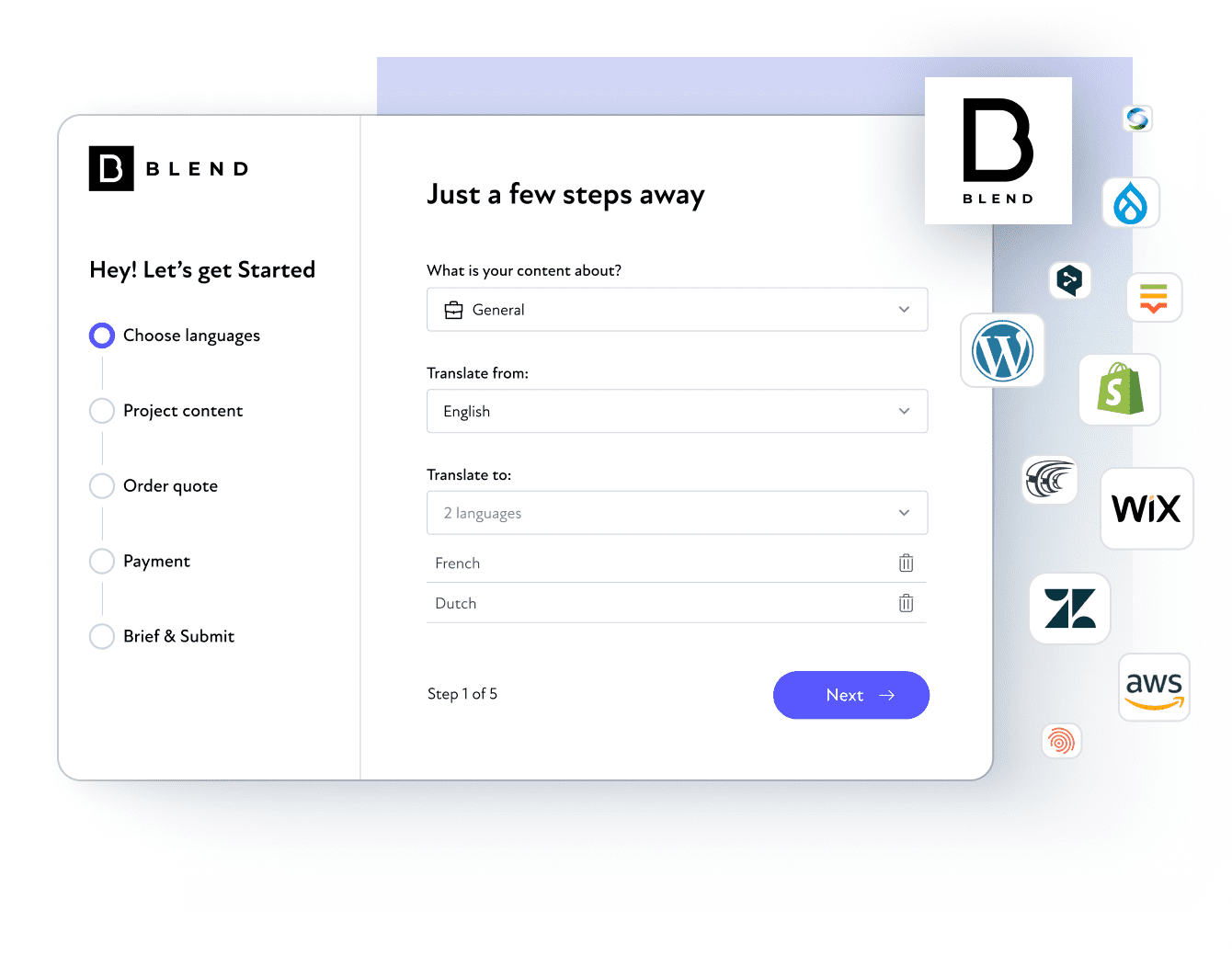


Um BLEND feito para ser perfeito
Serviços abrangentes para marcas focadas no crescimento







Segmento: Aplicativos móveis
Serviço: Localização de aplicativos

canal do YouTube em russo
Segmento: Criadores de conteúdo
Serviço: Localização de vídeo

em 50 idiomas
Segmento: Fintech
Serviço: KYC e extração de dados
Conte com a BLEND
Não somos do tipo “o que conta são os números”,
mas aqui estão alguns importantes

15

120

2,5B

7,5M

5,8mil
Conheça nossos "BLENDers"
Mais talentos, mais talentosos – A BLEND aloca mais de 25.000 tradutores e dubladores em todo o mundo para seus projetos
Explore o nosso catálogo de vozes- Avaliado, testado
- Classificado
- Recrutamento personalizado para o seu projeto exclusivo
- Alocado
- Comunicação direta com o cliente

Especialização no setor de traduções
Aproveitamento de uma vasta experiência para suas comunicações especializadas
- eLearning
- Dispositivos móveis e jogabilidade
- E-commerce
- Ciências biológicas
- Marketing de influência
- Fintech
- TI e software
- Experiência do cliente (CX) e Omnichannel
eLearning
Crie suas diversas equipes com melhores resultados, quer seu conteúdo seja corporativo ou acadêmico.
Saiba mais
Dispositivos móveis e jogabilidade
Ofereça uma experiência de jogabilidade envolvente em qualquer plataforma e em qualquer mercado.
Saiba mais
E-commerce
Abra sua loja virtual para o mundo com descrições de produtos locais e sem contato e SEO.
Saiba mais
Ciências biológicas
Transmita informações biomédicas e farmacêuticas vitais para profissionais da área de saúde de todo o mundo.
Saiba mais
Marketing de influência
Distribua conteúdo envolvente em todo o mundo, desde o roteiro até a pós-produção.
Saiba mais
Fintech
Combine tecnologia e talento para acelerar ativações de contas e manter a conformidade com as regulamentações financeiras.
Saiba mais
TI e software
Consiga especialistas no assunto e obtenha as mais recentes terminologias, tendências e aplicações.
Saiba mais
Experiência do cliente (CX) e Omnichannel
Aprimore as interações de chamadas e suporte com localização de script centralizada e gravação de alerta de voz.
Saiba mais
Crie suas diversas equipes com melhores resultados, quer seu conteúdo seja corporativo ou acadêmico.
Saiba mais
Ofereça uma experiência de jogabilidade envolvente em qualquer plataforma e em qualquer mercado.
Saiba mais
Abra sua loja virtual para o mundo com descrições de produtos locais e sem contato e SEO.
Saiba mais
Transmita informações biomédicas e farmacêuticas vitais para profissionais da área de saúde de todo o mundo.
Saiba mais
Combine tecnologia e talento para acelerar ativações de contas e manter a conformidade com as regulamentações financeiras.
Saiba mais
Consiga especialistas no assunto e obtenha as mais recentes terminologias, tendências e aplicações.
Saiba mais
Aprimore as interações de chamadas e suporte com localização de script centralizada e gravação de alerta de voz.
Saiba mais
O encontro da eficiência da IA com a experiência humana


Segurança, Proteção e Conformidade
A BLEND segue os mais altos padrões
Segurança
Conformidade
Privacidade




